APPENDIX: Dataset and methods
Hoaxlines collected the data via Netlytic, a platform designed for academic social media research, using the search query “RacistJoe,” from November 11 to 15. Once collected, we ran a “communication network discovery” and selected the following ties for the data visualization:
- User A replied to User B
- User A quoted User B
- User A retweeted User B
- User A mentioned User B (for 'original' tweets only)
We then downloaded the GEXF file and uploaded it to Polinode. Botometer scoring for the 100 most active accounts was obtained by taking tweet ID numbers from the RacistJoe dataset collected via Netlytic and entering them for collection into Communalytic, a Netlytic-related platform for data-based research on social media. Communalytic automatically assesses a dataset based on the outgoing (outdegree) links and ranks, in descending order, the top 100 most active accounts.
The top 100 accounts can be run through Botometer scoring, a machine learning tool trained on bot datasets that assess bot-like behavior in a selected account. The score goes from 0-1, and any score over 0.5 indicates an account is more likely to be marked as bot-like than a human.
Funding and conflicts of interest declaration
Hoaxlines generates no profit and, as yet, has accepted no donations. See Funding & Perspective for more information.
- This study is unaffiliated with any other organization or institution regardless of author scholarship or employment. The research and conclusions represent Hoaxlines alone. The views expressed in this report reflect sincere author impressions at the time of the study.
- The part(ies) responsible for the probable platform manipulation in this report are not addressed and cannot be assessed based on the information in this report alone. The inclusion of a name should not be taken to mean that the party was aware of or partook in platform manipulation as users have no control over who mentions them. The direction and nature of an edge can inform on the degree of participation.
Network details
November 12 data
- Network Name: RacistJoe—November 12
- Network Type: Directed
- Visible Nodes: 2,183
- Visible Edges: 2,386
- Average Total Degree: 2.19
- Network Density: 0.05%
- Avg Path Length: 1.06
- Diameter: 10.00
November 15 data
- Network Name: RacistJoe Hashtag—Nov 15
- Network Type: Directed
- Visible Nodes: 3,512
- Visible Edges: 3,910
- Average Total Degree: 2.23
- Network Density: 0.03%
- Avg Path Length: 1.07
- Diameter: 12.00
Netlytic Documentation
Uploading data from Netlytic to Polinode
Table of Contents
- Document Overview & Resources
- Introduction
- Application
- Audience
- Getting Started
- Signing in/ Registering
- Import / Create a dataset
- Text file / Cloud Storage
- Dataset Home Screen
- Account Information
- Preview Screen
- Text and Network Analysis
- Report Screen
- References
Polinode network metrics.
Node metrics
- Advanced Communities: This is an advanced version of the Louvain Communities algorithm (see below). The resolution parameter allows you to tune the size of the resulting communities—a resolution of 0 will place all nodes into a single community, whereas a resolution of two times the number of nodes will result in each node being assigned its own community. The default value of 1 will apply the algorithm without regard to the size of the resulting communities. There is also an optional maximum community size parameter that, if used, will limit the resulting communities to be no larger than the inputted value. For large networks, the algorithm is considerably faster with max size left blank. Read more here (opens new window).
- Average Neighbor Degree: Average Neighbor Degree for a node is the average number of edges (i.e. degree) that a node's neighbors have. For directed networks, you can specify whether to use in-degree or out-degree for each of the source and target nodes in the calculation. Read more here (opens new window).
- Betweenness Centrality: Betweenness Centrality for a node is the total number of shortest paths that pass through that node and if the Normalized option is selected, divided by the total number of shortest paths in the network. It is a measure of how much a node is a 'bridge' between other nodes in the network. Read more here (opens new window). Betweenness can be computationally expensive to calculate, particularly for large networks, which is why the option to sample a subset of nodes is provided as an input. If Apply Edge Weights is set to Yes then the inverse of the edge weights will be used such that a larger edge weight effectively reduces the distance between two nodes rather than increasing it.
- Binary Flag: Binary Flag is a helper metric that is equal to True for a node if for the selected attribute below is equal to one of the selected values below for that node. Otherwise, it is equal to False. It is particularly helpful when used together with the External edge metric.
- Brokerage: Brokerage here refers to Gould-Fernandez brokerage. Given an attribute, there are five kinds of brokerage possible: Coordinator, Consultant, Gatekeeper, Representative, and Liaison. This metric will count up and return the number of times that a node acted in each of those roles. Read more here (opens new window).
- Closeness Centrality: Closeness Centrality for a node is the reciprocal of its farness. The farness of a node is the sum of its shortest path distances from all other nodes. The greater a node's Closeness Centrality relative to other nodes, the closer it is on average to other nodes in the network. Read more here (opens new window).
- Clustering: The Clustering coefficient for a node is the fraction of possible triangles through that node that actually exists. The higher a node's clustering coefficient, the more embedded it is in the overall network. Read more here (opens new window).
- Connected Components: A Connected Component is a set of nodes that are connected to each other. A directed network will be treated as an undirected network for the calculation of Connected Components. Read more here (opens new window).
- Constraint: Constraint is related to the concept of structural holes and measures the extent to which a node can take advantage of structural holes in its network. Constraint will be higher if a node's connections are highly connected to each other, either directly or indirectly through a mutual connection. Read more here (opens new window).
- Core Number: Core Number for a node is the largest value k of all k-cores containing that node where a k-core is the largest possible subgraph in the network containing nodes with a Total Degree of k or more. Core Numbers can be helpful in the decomposition of large networks. Read more here (opens new window).
- Current Flow Closeness Centrality: Current Flow Closeness Centrality is similar to regular Closeness Centrality but instead of a shortest path measure for distance, effective resistance inspired by electric circuit models is used. Read more here (opens new window).
- Effective Size: Effective Size is related to the concept of structural holes and the redundancy of connections. It measures the number of people that the node is connected to but controlling for (i.e. reducing by) the redundancy of those connections. Read more here (opens new window).
- Efficiency: Efficiency is equal to effective size divided by total degree. If a node has no redundant ties then the effective size will be equal to total degree and efficiency will be equal to one. Efficiency is the proportion of a node's ties that are non-redundant. Read more here (opens new window).
- Eigenvector Centrality: Eigenvector Centrality is motivated by the idea that nodes connected to other nodes that are central should themselves be relatively central, i.e. being connected to a central node contributes more than being connected to a non-central node. It is not always well-defined for directed networks, and it's generally preferable to calculate Katz Centrality for directed networks. However, should you calculate eigenvector centrality for a directed network Polinode will return "left" eigenvector centrality (i.e. corresponding to the in-edges). Read more here (opens new window).
- External vs Internal: External vs Internal (EI) calculates, for a given attribute, the percentage of a node's edges that connect to nodes that do not share the same value for that attribute (external connections) vs connections to nodes that do share the same attribute value (internal connections). If type is Total the metric will be calculated for all edges, if type is In then the metric will be calculated only for a node's incoming edges, and if type is Out then only for a node's outgoing edges.
- Harmonic Centrality: Harmonic Centrality for a node is the sum of the reciprocals of the shortest path distances from that node to each other node in the network. It is closely related to Closeness Centrality with the key difference being that the reciprocal is taken for each distance rather than taking the reciprocal of the sums of the distances. Read more here (opens new window).
- HITS: Hyperlink-Induced Topic Search (HITS) for a node gives two metrics - Hubs and Authorities. A node has a relatively high Hubs score if it links to other nodes and a relatively high Authority score if it is linked to by other nodes.
- Identify Influencers: Identify Influencers is a heuristic that finds the most influential nodes in the network in the sense that together the count of those nodes and the nodes connected to those nodes is maximized, i.e. coverage of the network is maximized. Read more here. It is also possible to limit the influencers identified to certain attribute values by using the Limit by Attribute option. This is helpful if, for example, you want to identify influencers in an organization but only at the individual contributor level.
- In Degree: In Degree for a node is a straightforward measure of centrality—it measures the total number of nodes linking to that node.
- K Clique Communities: A K Clique Community is the union of all cliques of size k that can be reached through adjacent k-cliques where a k-clique is a group of k nodes that are all connected to each other and a k-clique is said to be adjacent to another k-clique if it shares k-1 nodes with it. Communities produced by this algorithm are generally not distinct and will overlap so an attribute is added for each community found. Read more here.
- Katz Centrality: Katz Centrality for a node considers not just the neighbors of that node but also their neighbors and so on, applying an attenuation factor of alpha so that the influence of nodes declines on every step away from the target node. Read more here.
- Load Centrality: Load Centrality for a node is the total amount of some commodity passing through that node when one unit of the commodity is sent from each node in the network to each other node in the network and the commodity is split equally at branching points and aggregated at meeting points.. Load Centrality is very similar to Betweenness Centrality and also measures 'bridging'. Read more here (opens new window).
- Louvain Communities: Louvain Communities are non-overlapping groups of relatively closely connected nodes found by an optimization algorithm. Read more here (opens new window).
- Out Degree: Out Degree for a node is a straightforward measure of centrality—it measures the total number of nodes that that node links to. Read more here (opens new window).
- Pagerank: Pagerank for a node is a ranking of relative importance in the network based on the structure of incoming edges for that node. It was originally designed to rank web pages. Similar to Katz Centrality, alpha is an attenuation factor. Pagerank for undirected networks will be calculated by transforming each undirected edge into two directed edges. Read more here (opens new window).
- Total Degree: Total Degree for a node is a straightforward measure of centrality. It is simply the total number of edges that that node has, i.e., for directed networks it is the sum of In Degree and Out Degree. Read more here (opens new window).
- Some of these metrics are only available for directed networks and some are only available for undirected networks. If a metric is not available for your network, you will see a message to that effect to the right of the dialogue.
Edge metrics
- Edge Betweenness: Edge betweenness measures the total number of shortest paths in the network that pass through an edge relative to the total number of shortest paths in the network overall. Just as for Node Betweenness, you can select a number of nodes to sample as a percentage of the total nodes in the network. If Apply Edge Weights is set to Yes then the inverse of the edge weights will be used such that a larger edge weight effectively reduces the distance between two nodes rather than increasing it.
Force-directed layout
This layout algorithm simulates physical forces on the network. You can think of it as applying an attractive force between nodes that are connected by an edge and simultaneously applying a repulsive force between all pairs of nodes. It is a continuous algorithm that will reach an equilibrium when these forces are in balance and the nodes stop moving. It needs to be started and stopped manually by clicking the start and stop buttons.
There is also one advanced setting for it and that is the Prevent Overlap option. By default, this option is No and you should always start running the layout algorithm with prevent overlap on No. Once the nodes have reached equilibrium, you may want to "tidy up" the layout by running the force-directed layout again with Prevent Overlap set to Yes. The same physical forces will be simulated but in this case, the relative size of nodes will be considered so that overlapping nodes are repelled from each other. It is significantly slower to run the algorithm with Prevent Overlap set to Yes, which is why it should only be applied after an initial equilibrium has been reached.
Network Properties as defined by Netlytic
There are five network properties Netlytic measure, which describe network characteristics, such as how individuals interact with each other, how information flows, and whether there are distinct voices and groups within the network.
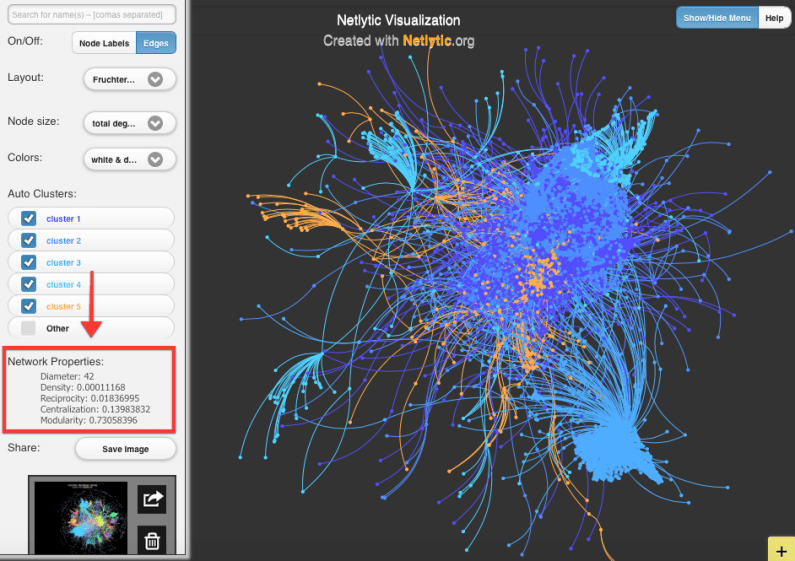
- Diameter calculates the longest distance between two network participants. This measure indicates a network’s size, by calculating the number of nodes it takes to get from one side to the other.
- Density is a proportion of existing ties to the total number of possible ties in a network. In other words, it is calculated by dividing the number of existing ties (connections) by the number of possible ties. This measure helps to illustrate how close participants are within a network. The density measure is complementary to diameter, as both assess the speed of information flow. The closer this measurement is to 1, the more close-knit the community/conversation, which suggests participants are talking with many others. On the other hand, if the value is closer to 0, this suggests amost no one is connected to others in the network.
- Reciprocity is a proportion of ties that show two-way communication (also called reciprocal ties) in relation to the total number of existing ties. It is measured by the number of reciprocal ties in relation to the total number of ties in the network (not all possible ties). A higher value indicates many participants have two-way conversations, whereas a low reciprocity value suggests many conversations are one-sided, so there is little back and forth conversation.
- Centralization measures the average degree of centrality of all nodes within a network. When a network has a high centralization value closer to 1, it suggests there are a few central participants who dominate the flow of information in the network. Networks with a low measurement of centralization closer to 0 are considered to be decentralized where information flows more freely between many participants.
- Modularity. To understand modularity, we first need to understand the concept of clusters in the network visualization. A cluster is a group of densely connected nodes that are more likely to communicate with each other than to nodes outside the cluster. Modularity, helps to determine whether the clusters represent distinct communities in the network. Higher values of modularity indicate clear divisions between communities as represented by clusters in Netlytic. Low values of modularity, usually less than 0.5, suggest that clusters, found by Netlytic, will overlap more; the network is more likely to consist of a core group of nodes.
Account traits
Formulaic handles
Recently created accounts
Return
Misleading presentation of Biden gaffe boosted by a bot-like network